1. Challenge
The coronavirus disease 2019 (COVID-19) pandemic, caused by the severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) virus, has generated an unprecedented global health crisis, with more than 2.7 million deaths worldwide. The challenge consists of designing robust machine learning algorithms to predict if the subjects of study are either COVID-19 positive or COVID-19 negative. See more here.
2. Motivations
The SARS-CoV-2 2019 (COVID-19) current infection or past infection can be respectively detected by a viral test and an antibody test. However, artificial intelligence could become handy to help researchers diagnose COVID-10 with X-ray images, accelerating the treatment of people infected and saving lives. I am highly concerned of improving well-being. Therefore, I picked this challenge.
3. COVIDx CXR-2
The COVIDx CXR-2 dataset contains images of COVID positive and negative chest radiography images from publicly available data sources: covid-chestray-dataset, etc. COVIDx CXR-2 is highly imbalanced. Indeed, around 86% of the train set is COVID-Negative CXRs (13793), thus only 14% is COVID-19 Positive CXRs (2158). It might be due to the percent positive, (percentage of all coronavirus tests performed that are actually positive) that is often low. For instance, a reasonable percent positive has to be below 5% according to the World Health Organization.
4. Pre-processing
The images were resized to 240x240 and normalized. We trained on RGB CXRs (3 channels). We did an histogram normalization for each channel of the CXRs to make pixel distribution uniform. The normalized CXRs look darker (Fig. 5).
Fig. 4: Before normalization
Fig. 5: After normalization
5. Model/Training
A ResNeXt50 has been used for the classification task. We chose this network because it is robust and highly modularized. We created a custom balanced train set from the original train set of COVIDx CXR-2 by including all the COVID-19 Positive CXRs (2158) and randomly picking the same number of COVID-19 Negative CXRs (2158). The new train set is pretty small comparing to the original one. Therefore, it was crucial to use data augmentation to improve the network generalization. The transformations have been applied in the following order: random rotation of 10°, random resize crop, brightness/contrast (0.2) and sharpness with a probability of 0.3.
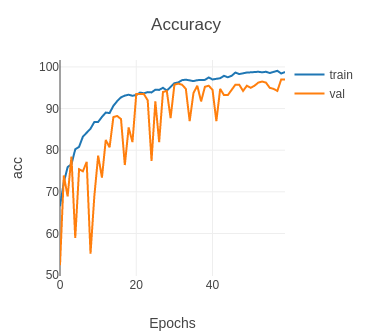
Fig. 6: Accuracy
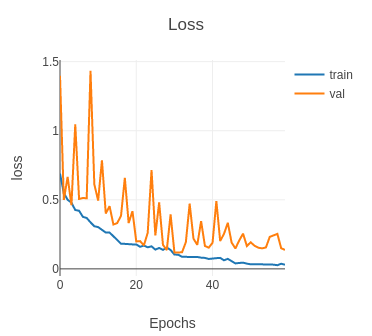
Fig. 7: Loss
The model has been trained on 60 epochs on a GTX 1060 (~3 hours) with batch size 32. The initial learning rate was equal to 0.001, 0.0005 (epoch 15), 0.00025 (epoch 30) and 0.00012 (epoch 45). The high fluctuations of the validation accuracy is due to the fact that the validation set is smaller than the train set. Indeed, the validation set is only 9.6% of the size of the train set. A reasonable ratio would have been equal to 25%. We used the test set of COVIDx CXR-2 as the validation set.
6. Results
The model reached 97% accuracy on the validation set, that is more than satisfying. However, the accuracy is not sufficient to conclude if the model can be used to detect SARS-CoV-2 2019 (COVID-19) infection. Indeed, we need to measure the sensitivity and the positive predictive value of each class. For instance, we do want to reduce the number of false negative for obvious health reasons.
7. Score
The score of the challenge to the final test results is based on the weighted sum of the Sensitivity, Positive Predictive Value (PPV), and the Runtime of the model. To be more specific, the final score is as follows:
Score=6SP+5SN+3PP+2PN-wt
Where SP and PP refer to the Sensitivity and PPV of the COVID-19 positive class. PN and SN refers to the Sensitivity and PPV of the COVID-19 negative class. t is the runtime of the algorithm and w is a non-negative weight.
8. Analyzis
When we tested our very first model on the competition set we discovered that the number of COVID-19 Positive CXRs was very low. 2 were detected positive out of 400, even though the model had 94% accuracy and a high score (15.80) on the validation set. As a result, we kept track of the number of positive cases during the training after each epoch.
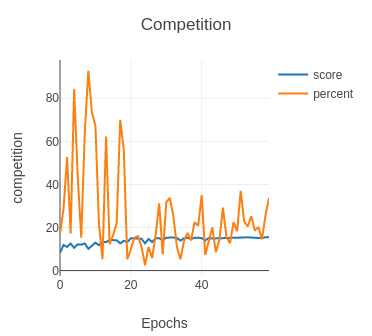
Fig. 8: Before penalization
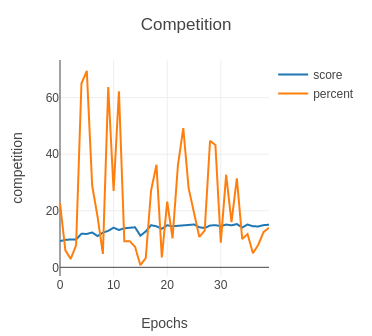
Fig. 9: After penalization
As you can see from the graph Competition (before penalization), the percentage (percent) of positive cases detected on the competition test oscillates a lot around 20% during the training. Please note that the score is the score of the validation set as we did not have access to the labels of the competition set. This behavior revealed that the competition set might contain very difficult images.
Our third submission scored 11.81 with 20% positive cases. Therefore, we had to improve our model to make it detect more true positive cases.
We saved the weights of our model when the accuracy was high (greater than 95%) and the percentage of positive cases detected greater than 30%.
We came up with a new model (training above) that scored 13.71 with an accuracy of 97% on the validation set and
34% positive cases detected on the competition test. Clearly, positive cases were still missing.
We decided to penalize more the false negative cases during the training. As you can see from the graph Competition (after penalization), the percentage (percent) of positive cases detected on the competition test is higher than before (epochs 20-30). At this point, we got our last model that scored 14.44 (fifth submission).
The accuracy on the validation set was lower: 93%, but it predicted fewer false negative cases on the competition set. Because the COVID-19 Negative CXRs are randomly selected at each training session, we fine tuned the model multiple times on different train sets.
Our final submission is the aggregation of our two previous submissions which scored 14.60 and ranked us 4th place.
9. Improvements (phase II)
Here are a non exhaustive list of possible improvements that we did not have time to try and that could be used for Phase II:
- Localized Energy-Based Normalization: efficiently normalize images from different sources, energy decomposition of the images in different bands [3].
- Combine Classification and Lung Segmentation: multi-target training can sometimes lead to better performance (e.g classifier connected to the bottle neck of an U-Net).
- Generative Adversarial Networks: generate more "data", especially positive cases, with GAN.
10. References
[1] Xie, Saining & Girshick, Ross & Dollar, Piotr & Tu, Z. & He, Kaiming. (2017). Aggregated Residual Transformations for Deep Neural Networks. 5987-5995. 10.1109/CVPR.2017.634. NEURAL NETWORKS:
[2] Wang, L., Lin, Z.Q. & Wong, A. COVID-Net: a tailored deep convolutional neural network design for detection of COVID-19 cases from chest X-ray images. Sci Rep 10, 19549 (2020).
[3] Philipsen, Rick & Maduskar, Pragnya & Hogeweg, Laurens & Melendez, Jaime & Sanchez, Clara & Ginneken, Bram. (2015). Localized Energy-Based Normalization of Medical Images: Application to Chest Radiography. IEEE transactions on medical imaging. 34. 10.1109/TMI.2015.2418031.